Robuste RAG-pipeline

robuste RAG-pipeline bouwen
Leer hoe je een efficiënte RAG-pipeline kunt opzetten voor het verwerken van ongestructureerde data.
RAG, ongestructureerde data, vector search, data pipelines, AI-tools
Een Retrieval-Augmented Generation (RAG) pipeline is cruciaal voor het verwerken van ongestructureerde data, die steeds vaker voorkomt in AI-toepassingen. Deze gids biedt een zes-stappen framework voor het effectief verwerken van ongestructureerde data via een RAG-pipeline.
Gestructureerde versus ongestructureerde data
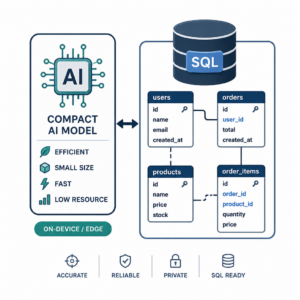
Gestructureerde data, zoals in spreadsheets en databases, is voorspelbaar en eenvoudig te verwerken. Ongestructureerde data, zoals tekst en afbeeldingen, vereisen geavanceerdere technieken zoals natuurlijke taalverwerking (NLP) en beeldherkenning. Traditionele data-oplossingen schieten vaak tekort voor deze complexe datatypes.
Belang van connectoren voor ongestructureerde data
De connectoren voor gestructureerde data zijn goed ontwikkeld, maar het ecosysteem voor ongestructureerde data blijft achter. Dit maakt integratie uitdagend en vereist vaak maatwerk. Het verbeteren van deze connectoren is essentieel voor de ontwikkeling van efficiënte RAG-pipelines.
“Vector search is essentieel voor het snel en contextueel relevant ophalen van informatie op basis van semantische gelijkenis.”
Om de uitdagingen van traditionele data-oplossingen voor vector search aan te pakken, moeten data worden omgezet in vectoren die semantische betekenis vastleggen. Vectorization speelt een cruciale rol in het effectief functioneren van RAG-systemen.
Een vier-stappen benadering omvat data-acquisitie, extractie, transformatie naar embeddings, en het laden in een vector database voor efficiënte zoekacties. Dit ontwerp zorgt ervoor dat zowel gestructureerde als ongestructureerde data accuraat en efficiënt worden verwerkt.
Waarom is dit interessant?
- RAG-pipelines zijn essentieel voor AI-toepassingen die ongestructureerde data gebruiken.
- Verbetering van connectoren verhoogt de toegankelijkheid van waardevolle ongestructureerde data.
- Vector search biedt aanzienlijke voordelen ten opzichte van traditionele zoekmethoden in AI-systemen.
- Het framework helpt ontwikkelaars bij het effectief opzetten van RAG-pipelines.
Relevantie 8/10
Het artikel sluit goed aan bij de interesses van gebruikers en ontwikkelaars van AI-tools, vooral diegenen die werken met ongestructureerde data en grote taalmodellen. Het biedt praktische inzichten en een gedetailleerd framework voor het bouwen van een RAG-pipeline, wat essentieel is voor moderne AI-toepassingen. Hoewel het niet direct nieuwe AI-modellen of technieken presenteert, biedt het wel waardevolle informatie voor het verbeteren van bestaande systemen.
Bron
Titel: Building a Robust RAG Pipeline: A 6-Stage Framework for Efficient Unstructured Data Processing
Taal: Engels
Gepubliceerd op 15-10-2024 om 18:38